


Deciding Which Encoding Converter to Use
The Text Encoding Conversion Manager provides two converters--the Text Encoding Converter and the Unicode Converter--that you can use to handle text encoding conversion on the Mac OS.The Text Encoding Converter is the primary converter for converting between different text encodings. It was designed to address most of your conversion requirements, and you should use it for most cases. You can use it to convert from one supported encoding to another. When you use the Text Encoding Converter, neither the source encoding nor the destination one must be Unicode, although they can be.
When you use the Unicode Converter, you always convert to or from Unicode; that is, either the source or the destination encoding must be Unicode. You should use the Unicode Converter if you are writing applications based in Unicode, such as a word processor or file system that operates in Unicode. Even when your application is not Unicode based, you might want to use the Unicode Converter for special cases where you want to control the conversion behavior more closely. The Unicode Converter is also the better choice if you want to map offsets for style run boundaries for styled text; the Text Encoding Converter does not offer this service.
The Text Encoding Converter
The Text Encoding Converter uses plug-ins, which are code fragments containing the information required to perform a conversion. A plug-in can handle one or more types of conversions. Plug-ins are the true conversion engines. The Text Encoding Converter provides a uniform conversion protocol, but includes no implementation for any specific kind of conversion. In other words, it supplies a generic framework for conversion but does none of the conversion work itself; rather, the plug-ins perform the actual conversions.This section looks briefly at plug-ins, Appendix A describes them in greater detail, and Mac OS Runtime Architectures gives general information about CFM-based plug-ins.
When you launch your application, the Text Encoding Converter scans the Text Encodings folder in the System Folder in search of available plug-ins. The Text Encoding Converter includes many predefined plug-ins--the Unicode converter is one of them--but you can also write and provide your own.
The Text Encoding Converter examines available plug-ins to determine which one or more to use to establish the most direct conversion path. Plug-ins can handle algorithmic conversions such as conversion from JIS to Shift-JIS. (Algorithmic conversions are different from conversion processes that use mapping tables. Mapping tables, which the Unicode Converter uses exclusively, are explained later.) Plug-ins can also handle code-switching schemes such as ISO 2022.
If a plug-in exists for the exact conversion required, then the Text Encoding Converter calls that plug-in's conversion function to convert the text. Such a one-step conversion is called a direct conversion. Otherwise, the Text Encoding Converter attempts an indirect conversion by finding two or more plug-ins that can be used in succession to perform the required translation. In such cases, the Unicode Converter might be treated as a plug-in.
For example, Figure 1-1 shows a conversion path from encoding X to encoding Y that uses both the Unicode Converter and another plug-in. The Unicode Converter converts encoding X to Unicode, then it converts the Unicode text to text in encoding Z. The other plug-in converts the text from encoding Z to encoding Y.
Figure 1-1 A possible conversion path used by the Text Encoding Converter
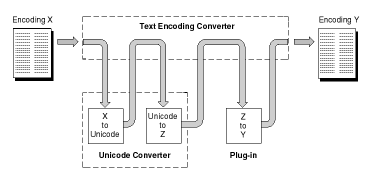
In general, you do not need to be concerned about the conversion path taken by
the Text Encoding Converter; it is resolved automatically. However, if you want to explicitly specify the conversion path, there are functions you can call to do so.When you use the Text Encoding Converter, you specify the source and destination encodings for the text. To convert text, you must create a converter object. This object describes the conversion path required to perform the text conversion. You can also create a converter object to handle multiple encoding runs. If the requisite plug-ins are available, the Text Encoding Converter can convert text from any encoding to runs of any other encodings.
When handling code-switching schemes, the Text Encoding Converter automatically maintains state information that identifies the current encoding in the converter object. Any escape sequences, control characters, and other information pertaining to state changes in the converter object are also detected and generated as necessary.
Because each converter object can maintain state information, you can use the same converter object to convert multiple segments of a single text stream. For example, suppose you receive text containing 2-byte characters in packets over a network. If the end of a packet transmission splits a character--that is, only 1 of the 2 bytes is received--the converter object does not attempt to convert the character until it receives the second byte.
In some cases, you may not be able to determine the encoding used to express text you receive from an unknown source, such as text delivered over the Internet. To minimize the amount of guesswork required to successfully convert such text, the Text Encoding Converter allows the use of sniffers. Sniffers are to text encodings what protocol analyzers are to networking protocols. They analyze the text and provide a list of the most probable encodings used to express it. Several sniffers are provided; you can also write your own sniffers when creating text conversion plug-ins.
The Unicode Converter
This section describes the Unicode Converter, which you can use to convert between any available non-Unicode text encoding and the various, supported implementations of Unicode. For background information on Unicode, the problems it addresses, and the standards bodies responsible for its emergence, see "About Unicode" (page 21) and Appendix B. For definition of some of the terms used in this section, see "Character Encoding and Other Concepts Fundamental to Text Encoding Conversion" (page 17).The Unicode Converter does not itself incorporate any knowledge of the specifics of any text encoding. Instead, it uses loadable, replaceable mapping tables that provide the information about any text encoding required to perform the conversion.
All information about a particular coded character set used in a text encoding is incorporated in a mapping table. A mapping table associates coded representations of characters belonging to one coded character set with their equivalent representations in another and accounts for the various conditions that arise when coded representations of characters cannot be directly mapped to each other.
The Unicode Converter can also handle conversions between Unicode and text encodings that use a packing scheme.
To convert text using the Unicode Converter, you must create a Unicode converter object, which references the necessary mapping tables and maintains state information. Because each Unicode converter object is discrete, you can retain several objects concurrently within your application, one for each type of conversion you need to make.
The Unicode Converter supports multiple encoding runs. An encoding run is a continuous sequence of text all of which is expressed in the same text encoding; a given string might contain multiple encoding runs, such as a sequence of text in Mac OS Roman encoding followed by a sequence in Mac OS Arabic. The Unicode Converter allows you to convert a single block of Unicode text to multiple runs in other text encodings. For example, you could convert a Unicode string into one that contains both Mac OS Arabic and Mac OS Roman encodings. You might find this useful when preparing text to display using the Script Manager.
Subtopics
- The Text Encoding Converter
- The Unicode Converter